
Sometimes you don’t want content to display in search results … but how do you get rid of it? Learn which four methods of removing content from a search engine’s index really work and when to use them.
Some content has no value to search engines. Content that is duplicative, outdated, or sensitive should be removed from a search engine’s index whenever possible to focus search engines on content you want to rank and to preserve crawl equity.

So how do you remove content from a search engine’s index to benefit your search engine optimization (SEO) program? The chart below gives you the answer at a glance. Read on for a detailed explanation of each method.
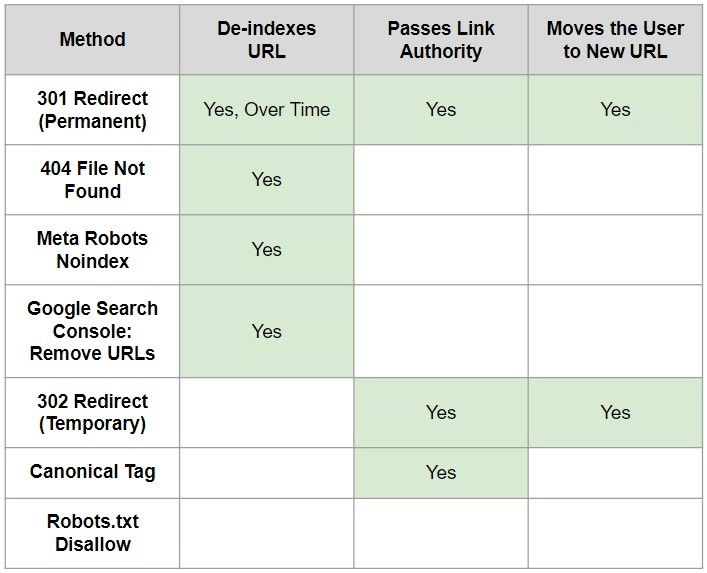
4 Ways To Remove Content From the Index
- 301 Redirects
Whenever possible, the 301 redirect is the preferred course of action because it accomplishes three important things:
- De-indexes URL: When a URL is 301 redirected, it is considered by Google to be an “alternate URL” that eventually “fades away” from use, in Google’s words.
- Passes Link Authority: One of the major ranking factors, link authority is the value passed to a URL through a link from another page. The 301 redirect preserves that valuable link authority and transfers it to the destination page.
- Moves the User to New URL: The primary action the user sees is the jump to the destination URL coded into the redirect. Not all content that needs to be removed from the index can be redirected because some content that has low value for SEO (like URLs with ecommerce sorting parameters) has high value to users.
- 404 File Not Found Errors
These errors are characterized by their sometimes-humorous error pages. More important to search engines, though, is the server header status code that they send. The 404 status code tells search engines that a URL no longer exists and to de-index the content. Unfortunately, any link authority that the URL might have had dies with the URL.
- Meta Robots Noindex Tags
The metatag lives in the head of the HTML code. It tells search engines not to index the page and is usually — but not always — obeyed. Search engines may still crawl the page to determine that the page is still noindexed if the search engine considers the page highly valuable, especially if there are a lot of links to the page from other sites.
- Google Search Console’s Remove URLs Tool
This method only works for Google, obviously, but it is the strongest signal you can send to de-index a page. The removal takes effect quickly — typically within a day. However, the removals are temporary, lasting “about” six months. If you want to permanently remove the URL from the index, you’ll need to use another method. You’ll also want to take care using the removal tool — people have accidentally removed content that they wanted to be indexed, including entire sites.
3 Ways That Do Not Remove Content From the Index
- 302 Redirects
Most redirects you’ll make will be 301 redirects. However, if the redirect is truly temporary and the content you’re redirecting will return to that same URL, then a 302 redirect is the right move. A 302 redirect is a server header status code that moves the user and is a weak signal to search engines to pass link authority to the page being redirected to. They don’t prompt deindexation, though. If you want to deindex content, either a 301 redirect or a 404 error is the correct way to do that via a server header status code.
- Canonical Tags
Also found in the head of the HTML file for a page of content, the canonical tag’s sole reason for existence is to reduce duplicate content. When there are multiple copies of a page available at different URLs, the one version that is the page that should be ranked is marked canonical. All of the versions of the page would have a canonical tag pointing to the one canonical version of the page that should rank typically, and the other versions would be considered alternate pages. The canonical tag lets you request the page you want to be canonical, but Google can and does choose its own canonical version if it disagrees with your tag. As such, the canonical tag is interpreted as a suggestion rather than a command.
- Robots.txt Disallows
The robots.txt file is an archaic text file that lives at the root of your site. For example, https://site.com/robots.txt would be the URL pattern at which you can find the robots.txt file for any site that has one. The file contains allow and disallow statements that identify URLs that should or shouldn’t be crawled. Sites commonly disallow shopping cart or account pages, for example. Search bots visit the robots.txt file before they crawl a site to identify which pages they can crawl and which they should not. Robots.txt files are used to keep bots from crawling content, but they don’t prompt de-indexation of the disallowed content.
How To Remove Content From Search Engine Indexes
So now you know what each method of content removal does, but you still don’t know when to use them to remove your content. The good news is that we can answer that question by walking through a couple of simple questions. The flow chart below will help, and I’ll explain each step below.
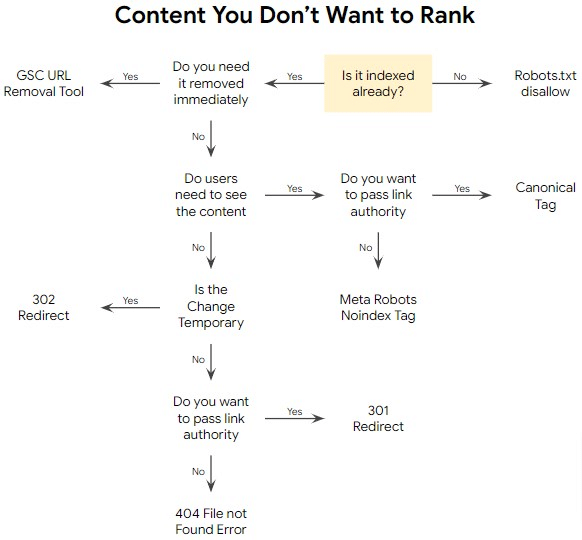
Is It Indexed Already?
The first of the six questions shown highlighted in yellow above deals with whether the content you want to keep out of the index is already indexed. If it’s not, using a robots.txt disallow will keep it from being indexed in the future. It won’t, however, de-index the content once it has been indexed. If the content is already indexed, you need to move to the next question.
Do You Need To Remove It Immediately?
If the content is sensitive or incorrect in a way that will affect finances or lives, then you might not have the time it would take to deindex content the usual way. Google Search Console provides a URL Removal tool that can de-index content quickly, typically within a day.
Do Users Need To See the Content?
A typical reason to remove content is that it’s a duplication of other content. Some of that content is useful to users. For example, sorting parameters in ecommerce sites don’t need to be indexed, but customers need to be able to use them. Redirecting the sorting parameters would render sorting impossible, which would obviously be undesirable for an ecommerce site. You may decide that other types of content could be removed from the server without affecting users. If URLs are useful to users, you’ll need to use a noninvasive method like a canonical tag or a meta robots noindex tag to remove content from the index. If the content is just duplicative, outdated, or otherwise not useful to users, a 301 redirect is almost always the right move.
Is the Change Temporary?
If the content is truly going to be removed temporarily and will later come back, then a 302 redirect is the right answer.
Do You Want To Pass Link Authority?
The answer to this question is almost always yes, so either a 301 redirect or canonical tag — depending on whether the users need to see the content or not — is nearly always the answer when you get to this question. The authority and increased ability to rank that are earned when other sites link to yours is like gold — extremely valuable and difficult to acquire. However, if you don’t care about passing link authority, you can use either a meta robots noindex tag or a 404 error, depending on whether the users need to see the content or not.
The next time you need to remove content from a site, whatever the reason, remember that there are four ways to do it correctly and three that won’t help you. But each of the seven actions discussed here plays a valid role in the management of your SEO program. Know the tools available in your toolbox, and use them well.






